
TOOLS FOR ADDING AND EXTRACTING MARC METADATA TO PDF DOCUMENTS
Abstract
Author(s): M.R. Ramesh
The proliferation of information and communication technologies with electronic publishing resulted in the production of abundant digital documents. These digital documents are in the form of any of the well established file formats specifications such as TIFF(Tagged Image File Format), JPEG(Joint Photographic Expert Group), PDF(Portable Document Format), HTML(Hypertext Markup Language), etc. often the metadata of digital documents is not properly added to the document properties of the files. It is also for the digital documents pertaining to e-books whose metadata is generally stored and access to metadata of printed documents were well established practices by the library community for a reasonable period using various cataloguing, classification schemes, indexing and retrieval mechanisms. The metadata for the digital documents generally maintained in an external database for storage and retrieval purpose. In order to make the digital documents more meaningful and describing, it is $necessary to store the metadata inside the files for easy identification and retrieval. This paper describes the various tools for adding and extracting MARC metadata to PDF files of storing and retrieving metadata within the digital documents.
Call for Papers
Authors can contribute papers on
What is Your ORCID
Register for the persistent digital identifier that distinguishes you from every other researcher.
Social Bookmarking
Know Your Citation Style
American Psychological Association (APA)
Modern Language Association (MLA)
American Anthropological Association (AAA)
Society for American Archaeology
American Antiquity Citation Style
American Medical Association (AMA)
American Political Science Association(APSA)

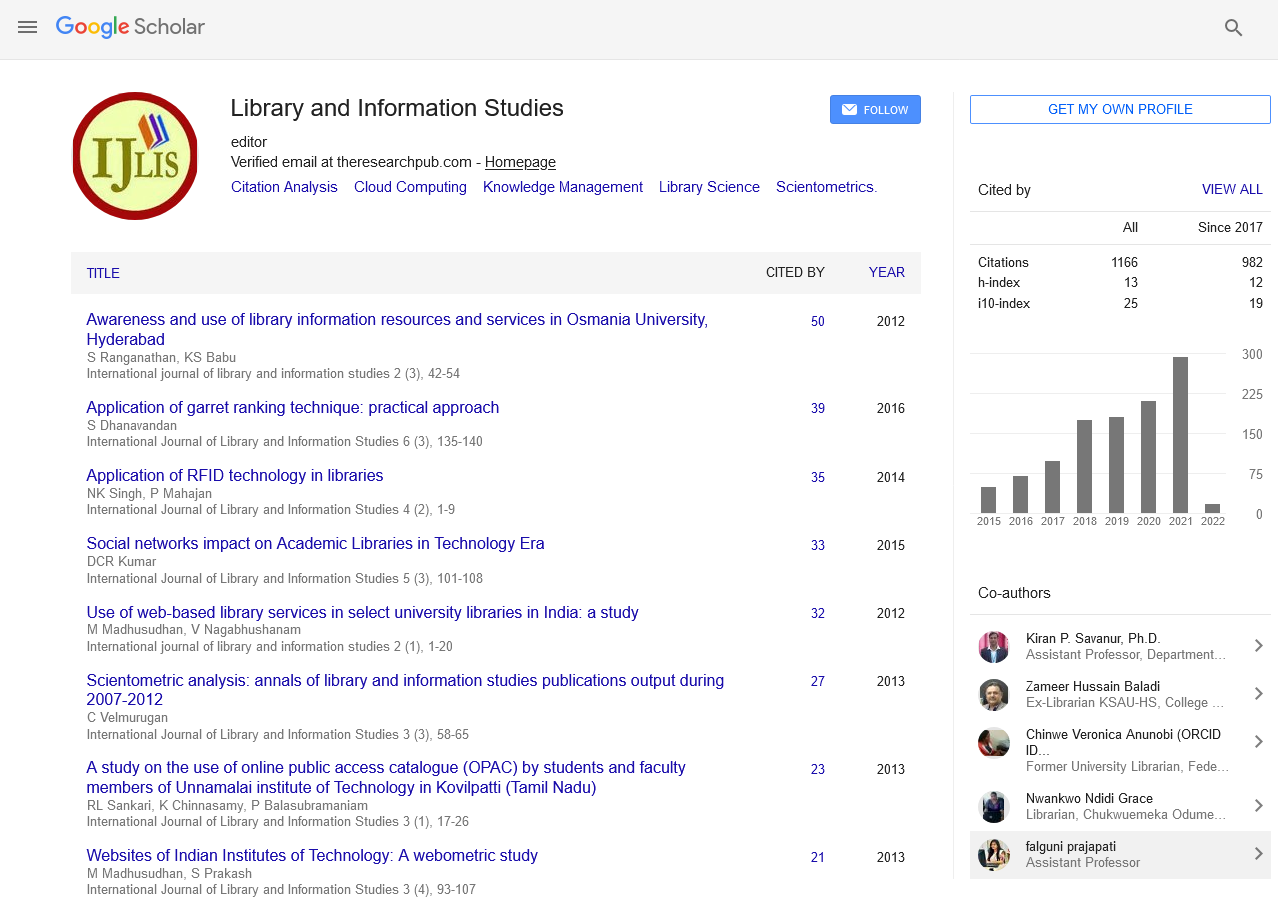
Google Scholar citation report
Citations : 1680
International Journal of Library and Information Studies peer review process verified at publons
Indexed In
Bibliography & Citation Tools
